Respan
Route, track, and debug all LLM traffic.
About Respan
Advertiser Disclosure: Futurepedia.io is committed to rigorous editorial standards to provide our users with accurate and helpful content. To keep our site free, we may receive compensation when you click some links on our site.
Key Features
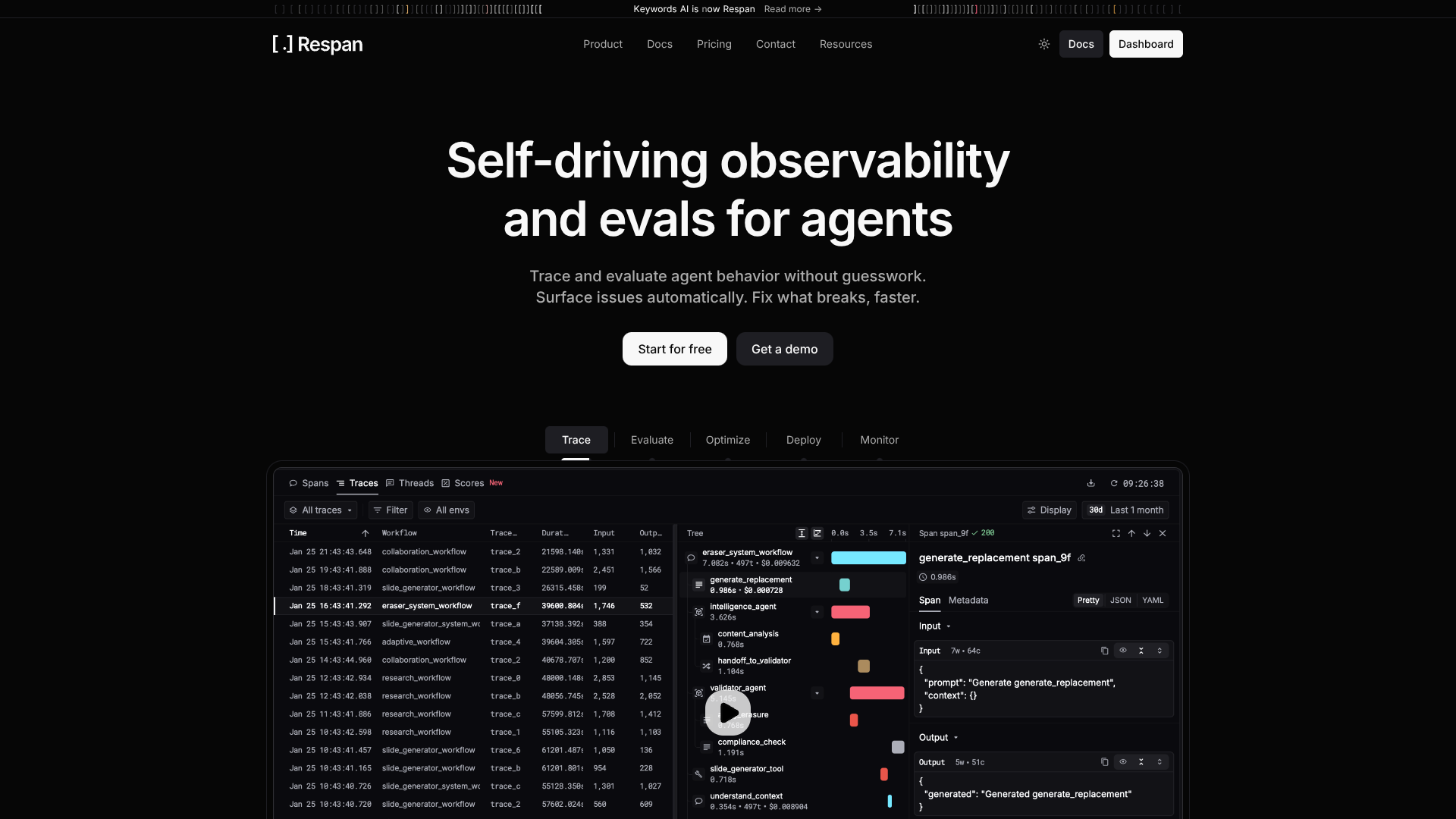
- Unified LLM gateway: Route requests through one base URL while still choosing models across multiple AI providers and tools.
- Token, cost, and latency analytics: Dashboard views show token usage, per-request cost, latency distributions, and error rates across all calls.
- Tracing SDK with decorators: OpenTelemetry-based SDK for Python and JavaScript uses decorators such as @workflow and @task to capture end-to-end traces, auto-attaching LLM calls.
- Rich attribution metadata: Attributes like customer_identifier, trace_group_identifier, and custom metadata help teams slice metrics by user, project, experiment, or environment.
- Flexible logging modes: Teams can either proxy traffic through the gateway by switching the base URL or log requests asynchronously via a dedicated logging endpoint.
Pros
- Strong LLM observability: Fine-grained analytics make it much easier to understand where tokens, time, and errors are going.
- Quick integration paths: Many stacks only need a base URL change or a few decorators to start emitting traces.
- Provider flexibility: Support for several model vendors and speech-to-text APIs suits teams that like to experiment.
- Agent-friendly tracing model: Concepts such as workflows, tasks, agents, and tools line up well with modern agent architectures.
Cons
- Requires routing changes: Applications must adopt the gateway or SDK, which may feel heavy for very simple prototypes.
- Data governance questions: Security teams will want to review how prompts and outputs are stored and who can access logs.
- Pricing transparency: Public materials do not clearly show per-plan prices, which complicates early budgeting.